DLX 处理器程序设计
实验目的
学习使用 DLX 汇编语言编程,进一步分析相关现象
实验原理
掌握向量运算算法和编程方法。由于操作数为双精度,需要使用操作浮点双精度的指令。
本次使用到的指令为
- ADDD 浮点加指令,其命令格式为
rd,rs1,rs2,rs1 和 rs2 将加到 rd 上。 - ADDI 立即数加指令,其命令格式为
rd,rs1,immediate,rs1 和一个立即数将加到 rd 上。 - SD 存储浮点数指令,其命令格式为
offset(rs1),rd,将 rs1 对应空间的数存储在 rd 上。 - LD 读取浮点数指令,其命令格式为
rd,offset(rs1),将 rs1 对应空间的数取到 rd 上。 - BNEZ 判断指令,其命令格式为
rs1,name,如果 CPR 寄存器不为零,则继续执行 name 部分。
实验步骤
-
自编一段汇编代码,完成两双精度浮点一维向量的加法(或乘除法)运算,并输出结果。向量长度 >=16。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39.data
VecLen: .word 16
Vector1: .double 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16
; vec1=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16]
Vector2: .double 2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32
; vec2=[2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32]
; 声明向量长度以及两个向量1、2
Printf1: .asciiz "The result is\n"
Printf2: .asciiz "%f\t"
.align 2
PrintfHead: .word Printf1
PrintfValue: .word Printf2
result: .space 8
; 打印数据空间的申请
.text
main:
addi r14,r0,PrintfHead
trap 5
lw r20,VecLen
addi r2,r0,0
loop: ; 循环读入向量
ld f0,Vector1(r2)
ld f2,Vector2(r2)
addd f4,f0,f2
; 主要的加法运算
sd result,f4
addi r14,r0,PrintfValue
trap 5
addi r2,r2,8
subi r20,r20,1
bnez r20,loop
trap 0
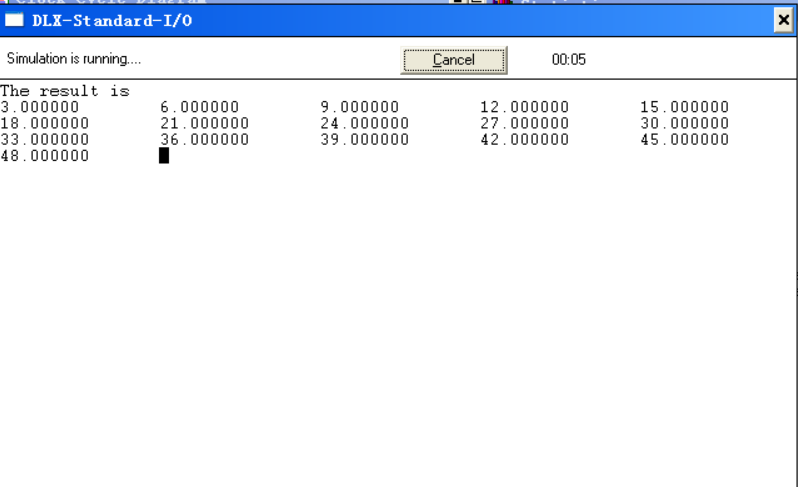
; 系统中断,输出结果 "The result is 3.000000, 6.000000, ...."程序,运行结果为下图
![]()
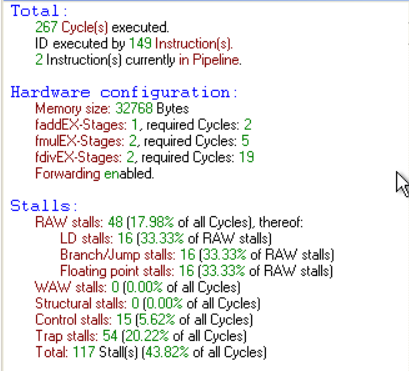
数据统计为下窗口所示:
![]()
![]()
-
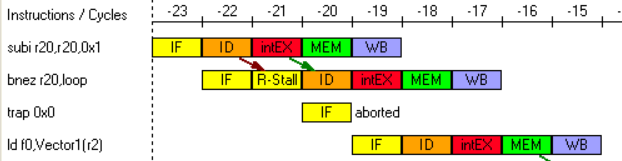
观察程序中出现的数据/控制/结构相关。
![]()
数据相关:对当前指令的操作数寄存器进行操作(EX)的时候,前几条指令的运算结果还未写回(WB)结果寄存器,产生了数据相关。
典型指令组合
1
2subi r16,r16,0x1
bnez r16,Loop控制相关:由于系统按照预测成功来执行指令,所以执行 bnez 后会马上将其下一条指令 trap 读取进来
典型指令组合:
1
2bnez r20,Loop
trap 0x0程序中并没有出现结构相关。因为整体仅仅做了一次简单的加法。
-
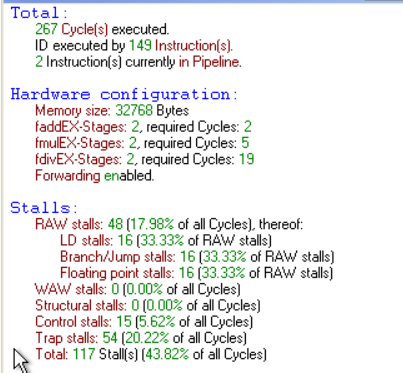
浮点运算部件带来的影响
![]()
![]()
增加浮点加法器的数量后,程序执行的性能并未得到提升。
-
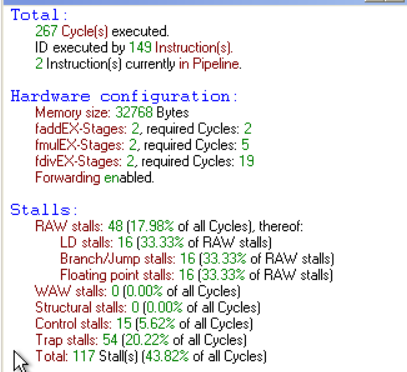
Forward 组件的影响
![]()
![]()
关闭 Forward 后,运行时间由 267 个周期增加到 333 个周期,可计算 Forward 技术为该程序带来了 333 / 267 = 1.25 的加速比。且 Forward 技术明显减少了 RAW stalls,降低了数据相关的数量。
-
转移指令的影响
![]()
![]()
成功时,已经进入取指阶段的指令会被放弃(aborted),转入转移的目标指令的取指操作,造成流水线断流;若转移失败,已经进入取指阶段的指令继续进入译码阶段,流水线不断流。