借助 ANTLR 分析代码中的漏洞
实验目的
通过分析特定漏洞代码特点,借助 ANTLR 分析代码中的特定漏洞。
实验条件
- Windows 10 专业版
- JDK 1.8 版本(64 位,版本号为 1.8.0_202)
- ANTLR 环境 ——ANTLR 4
实验内容
漏洞描述
-
Double Free,多次释放漏洞,是对指向同一个地址的指针进行两次及以上的操作,可能会造成任意代码执行或其他非预期危害。虽然一般把它叫做 double free。其实只要是
free一个指向堆内存的指针都有可能产生可以利用的漏洞。 -
一段简单的漏洞代码示例如下所示,其中对
char* buf2R1所指向的内存进行了两次释放操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int main(int argc, char **argv) {
char *buf1R1;
char *buf2R1;
char *buf1R2;
buf1R1 = (char *) malloc(BUFSIZE2);
buf2R1 = (char *) malloc(BUFSIZE2);
free(buf1R1);
free(buf2R1);
buf1R2 = (char *) malloc(BUFSIZE1);
strncpy(buf1R2, argv[1], BUFSIZE1-1);
free(buf2R1);
free(buf1R2);
} -
double free 的原理其实和堆溢出的原理差不多,都是通过 unlink 这个双向链表删除的宏来利用的。只是 double free 需要由自己来伪造整个 chunk 并且欺骗操作系统。
语法识别
利用 ANTLR4 的 C++ 语言语法规则文件,对漏洞代码进行分析。
-
右键点击 g4 中的 translationunit,选择 test rule,将那个有漏洞的 C 代码制作成 expr 文件后,作为输入。
-
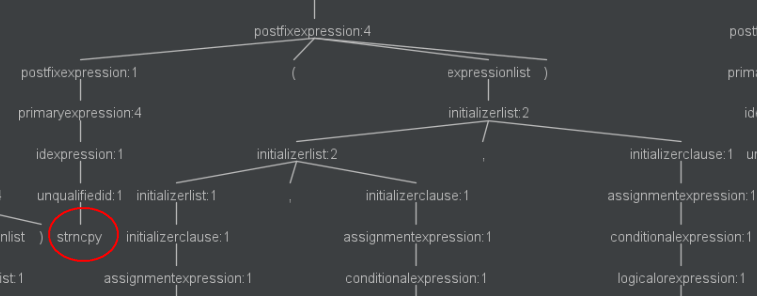
然后在输出位置就可以看到好大一棵 parseTree 了!右键另存为一张图。
![]()
-
ParseTree 全貌,其中左边的一小撮是函数头定义,右边的一大撮才是函数体定义。
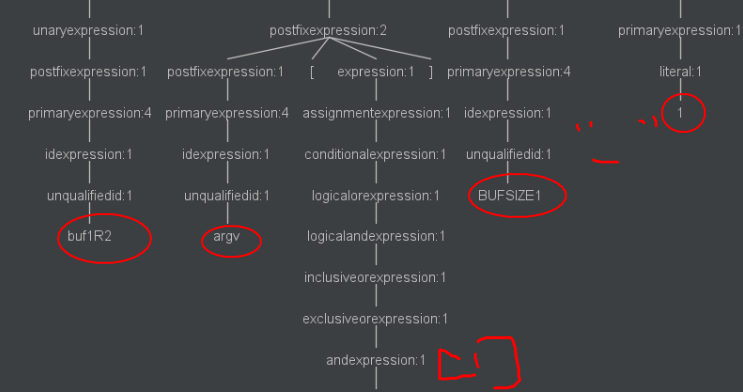
- 首先定义了三个字符指针型变量
buf1R1、buf2R1、buf1R2![]()
- 然后为
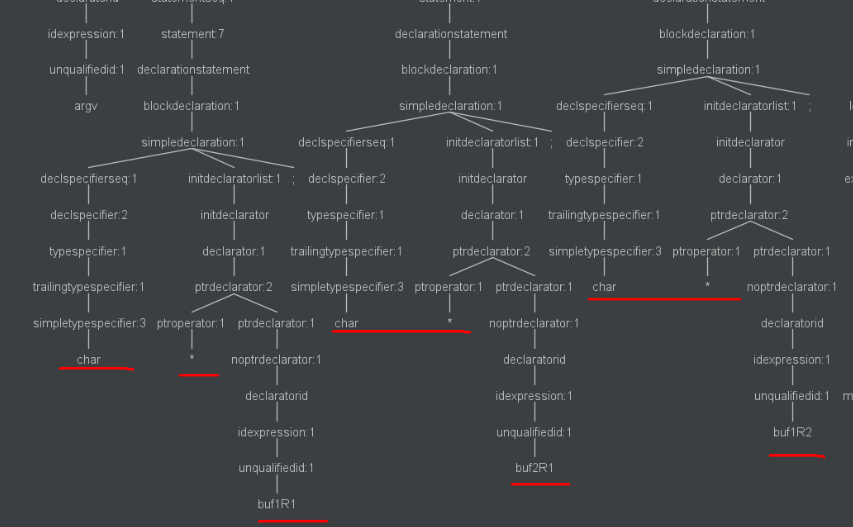
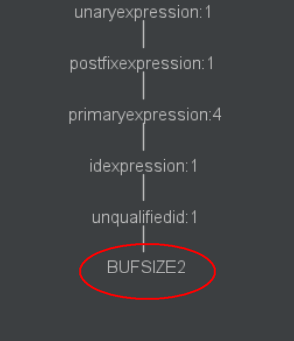
buf1R1分配了BUFSIZE2大小的空间,为buf2R1分配了BUFSIZE2大小的空间![]()
![]()
- 首先定义了三个字符指针型变量
-
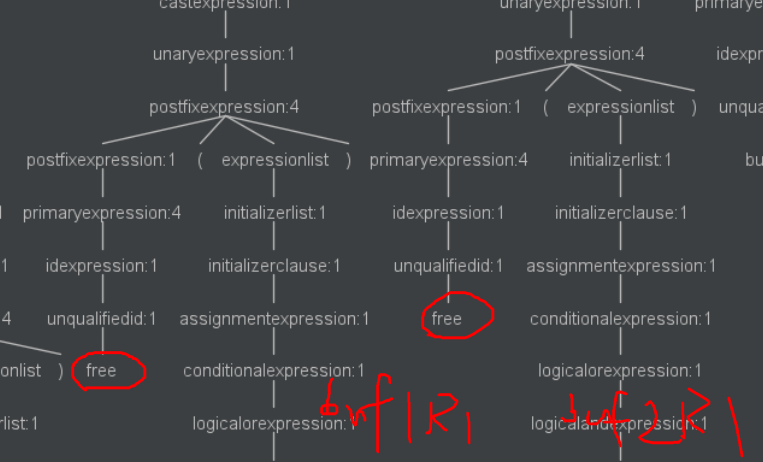
紧接着
free掉它们![]()
-
为
buf1R2分配空间,大小为bufsize1![]()
-
把
argv[1]中的内容复制到buf1R2所指空间中![]()
![]()
-
最后的两个
free语句都在语法分析树的右侧![]()
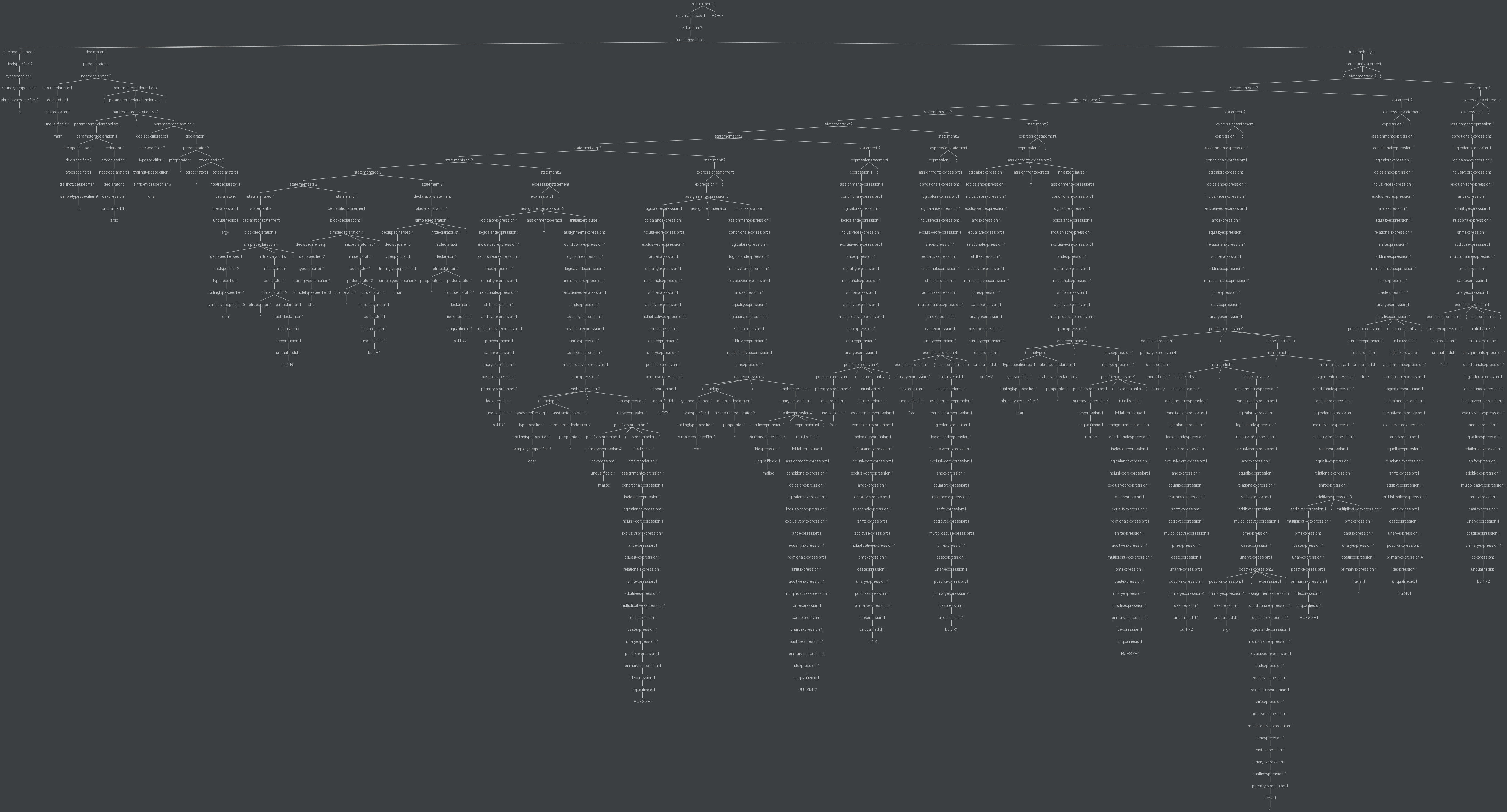



从语法分析树中看不出任何问题,因为这个存在漏洞的代码是语法正确的,而且也符合 C 语言语法结构。所以我们在编写相关代码时,要自行检查指针的使用情况,最好在释放指针所指向的空间后,将其置为NULL。
实验总结
本实验中通过学习带有漏洞的 C 语言代码,了解到一些常见的二进制相关漏洞,借助到 C 语言的语法规则文件,对漏洞代码进行分解研究,了解到了我们所写的程序通过语法树展开后的样子,并试着提取其规则,编写漏洞描述 xml 文件。
中途遇到了 IntelliJ IDEA 无法解析规则,找不到 start rule 的问题,后来通过在 cpp14.g4 文件中右击 translationunit 规则,点击 test translationunit rule 找到了语法树的生成点,从而成功在 ANTLR Output 中看到了所生成的语法树。