ANTLR 语言识别工具
实验目的
- 了解 ANTLR 语言识别工具,安装 ANTLR 环境,熟悉 ANTLR 的使用。
- 掌握使用 ANTLR 构建的语法分析器和树解析器分析语言,通过 ANTLR 实现语法分析过程。
实验条件
- Windows 10 专业版
- JDK 1.8 版本(64 位,版本号为 1.8.0_202)
- ANTLR 环境 ——ANTLR 4
实验内容
安装 ANTLR
个人所用的集成开发环境中提供 ANTLR 插件的安装,故可直接进入插件下载功能中下载该插件。运行时环境配置过程和安装过程不再赘述。
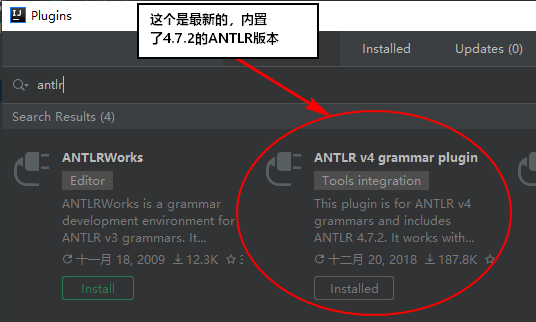
安装以后,下方工具栏会多出两个窗口:ANTLR Preview 和 Tool Output。


Preview 中可以显示 Parse tree,从而省去了在控制台中输入-gui命令的麻烦。
使用 ANTLR 实现实数的四则运算
要求
创建 ANTLR 语法文件expr.g4,解析如赋值语句a = 5.5 和表达式a+4*3÷2-1 这样的语句。
- 要验证所编写的文法是否正确,可使用 TestRig 测试语法,在 CMD 中输入
-gui可直观展示其语法分析树。 - 创建 expr 文件(如 test.expr,输入一个表达式)检验程序是否能够正确运行和计算四则算式。
-
文法设计
1
2
E -> E OP E|VAR = E|E'; E'-> D; OP: [+|-|*|/]; D:[0-9]+; VAR:[a-zA-Z]+;由此编写的
expr.g4文件如下:(还考虑了一些换行及空格因素)expr.g4 1
2
3
4
5
6
7
8
9
10
11
12
13
14
grammar expr;
exprs : setExpr | calcExpr ;
setExpr : id=ID '=' num=NUMBER ;
calcExpr: calcExpr op=(MUL | DIV) calcExpr | calcExpr op=(ADD | SUB) calcExpr | factor ;
factor: (sign=(ADD | SUB))? num=NUMBER // 计算因子可以是一个正数或负数
| id=ID // 计算因子可以是一个变量 ;
WS : [ \t\n\r]+ -> skip ;
ID : [a-zA-Z]+ ;
NUMBER : [0-9]+('.'([0-9]+)?)? ;
ADD : '+' ;
SUB : '-' ;
MUL : '*' ;
DIV : '/' ; -
运行结果
控制台工具显示如下
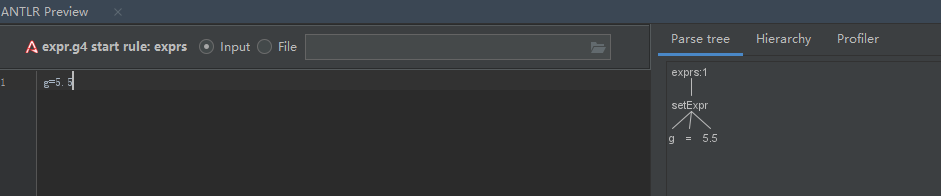
Main 函数如下
1 |
|
运行结果如下

本次测试的式子为a+4*3/2-1
控制台工具显示如下

Main 函数如下
1 |
|
 从输出来看,对语法树的遍历过程几乎遍及了句子的每一个结点。由于最后得到的句型是一个类似于
从输出来看,对语法树的遍历过程几乎遍及了句子的每一个结点。由于最后得到的句型是一个类似于a + <数字>的格式,所以它输出NaN,与预期一致。
a是与前一个赋值语句分开输入的,所以它并没有被定义值
本次测试的式子为1+4.5*2-3/3
Main 函数代码类似,控制台工具显示如下

代码输出结果如下
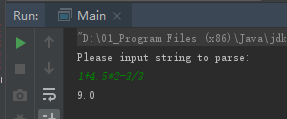
得到了正确的输出结果,证明我们写的语法解析是正确的。
- 针对除 0 错误,程序可以顺利显示出
Infinity,没有中断程序
![]()
- 输入过长也不会中断程序
![]()
- 符号错误需要单独处理
,需要一个ID,NUMBER,加号或减号")


,需要一个ID,NUMBER,加号或减号")
这说明符号错误需要单独处理,java 中可以使用 try-catch 来完成这项工作。除此之外,也可从前端角度考虑,提前检验用户输入。
总结
这个解析过程是怎么实现的呢?
- 在生成 ANTLR 识别文件时,实际上生成了很多个 java 和 token 源文件。
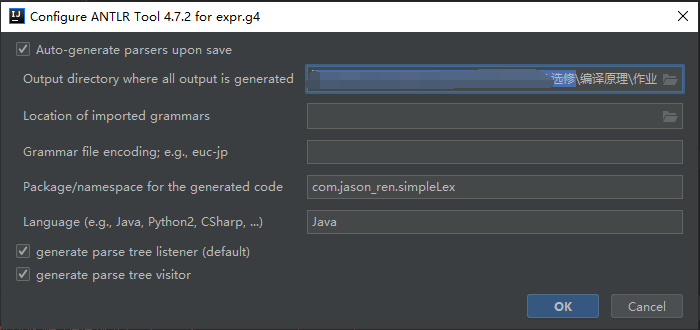
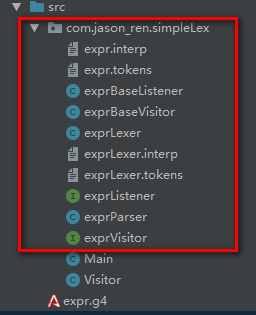
-
有两个 tokens 文件和六个 java 文件,
Listener和Visitor是两个接口,Listener中定义了一些退出或进入一个表达式中所进行的语法动作,Visitor中定义了遍历语法树中项目的返回动作,一个语法项对应一个visit函数。具体由xxBaseListener或xxBaseVisitor来实现。默认状态下,所有的实现都是空的,我们可以扩展xxBase[Listener|Visitor]类,自己定义语法动作。本实验中,只需要实现Visitor的内容即可,不过由于上下文的关系,我们需要自建一个Context类,负责上下文内容的保存和识别。 -
重写
visit函数:1
public <你需要的返回值> visit<A>(xxParser.<A>Context ctx)
-
.tokens 文件中将语法常量对应了一个整数数值,方便常量的建立。.interp 文件则记录了字面值。
-
Parser 中,对每一个语法变量,生成了很多上下文相关的方法(xxContext)。其中的某些常量在前面所述的.tokens 文件中可以找到。
-
Lexer 中,则存储了字面量及其相关方法,某些内容可在.interp 文件中找到。
-
而所有开头的 xx 来自于语法文件第一行的 grammar xx,即为语法名。
-
Visitor实现完成后,在主函数中建立visitor对象,调用visit语法树方法,将用户输入作为参数传入,其返回值即为语法分析结果。
1 | public class Visitor extends exprBaseVisitor<Double>{ |
- 目前实现的版本中,可以正确地进行运算,但还没有实现连续赋值功能,也没有考虑到多语句的分隔及分开解析,例如输入
"a=1 a+1"后不能得到2,可能需要修改Context类和Visitor类中的代码,使其可以记录上下文信息,将a的值存入暂存区。